

The Illusion of Stability: The Internet Runs on a Handful of Companies
Everything works, until the day it doesn't.


Hey there 👋
A few months ago, I arrived at work expecting a normal day.
Instead, I spent a good chunk of it waiting.
Our website had become inaccessible, and since a large portion of my work revolves around publishing, editing, and managing content online, there wasn’t much I could do until things came back.
And it wasn’t just us.
When major cloud providers experience problems, the effects spread far beyond a single company. Over the past few years, outages involving Amazon Web Services (AWS), Microsoft Azure, and Cloudflare have repeatedly disrupted services used by millions of people.
Most of us rarely think about the infrastructure that makes modern technology work. We just assume everything will be there when we need it. And most of the time, it is. But every now and then, something breaks and we’re reminded that the digital world depends on infrastructure that can go down and disrupt the whole world.
The funny thing is, modern technology often feels more reliable than ever. Yet at the same time, many of the systems we rely on have become increasingly centralized, interconnected, and dependent on a surprisingly small number of companies.
And that's what this article is about: how the internet ended up here, why so much of modern life depends on a handful of critical services, and what we can personally do about it.
How the Internet Became More Centralized
When the web started becoming mainstream during the 1990s, the digital world was far more distributed than it is today.
Websites typically ran on their own servers. Companies managed much of their own infrastructure. Services were separated from one another and if one website experienced problems, the impact was usually limited to that particular website.
With the passage of time, that began to change.
As internet services became larger and more complex, companies started looking for ways to reduce costs and simplify operations. Running servers is expensive. Maintaining data centers is difficult. Scaling infrastructure for millions of users requires expertise that many organizations simply don’t have.
Cloud computing solved a lot of those problems.
Instead of purchasing hardware, building server rooms, and hiring teams to manage everything, companies could rent infrastructure from providers like Amazon Web Services, Microsoft Azure, and Google Cloud.
The advantages were enormous - startups could reach global audiences without building their own infrastructure. Businesses could scale faster than ever before. Developers could focus on building products instead of managing hardware.
The cloud, in a way, transformed the internet, but every solution comes with tradeoffs.
When more organizations moved into the same cloud platforms, dependence became inevitable. Thousands of companies that once operated independently now relied on the same providers, the same infrastructure, and in many cases, the same underlying services.
The same thing happened across other parts of the internet - companies adopted the same content delivery networks. The same authentication providers. The same software repositories. The same security certificate authorities.
Each decision made sense on its own.
Collectively, however, they created a very different internet than the one that existed decades ago.
The Hidden Fragility of Modern Technology
The Companies Holding Up the Internet
Some people might argue that the internet itself remains distributed. While that may be true, many of the services running on top of it have become heavily centralized.
Cloudflare is a good example - the company provides a lot of services for millions of websites. Depending on the measurement used, Cloudflare helps power or protect roughly one-fifth of the web, making it one of the most important pieces of infrastructure most people have never heard of. Recent outages have demonstrated just how much disruption a single failure can create when so many services depend on the same provider. In June 2026, another major disruption involving internet infrastructure providers affected many services, once again demonstrating how failures can ripple across large portions of the web.
Amazon Web Services represents another major concentration point - thousands of companies no longer operate their own infrastructure. Instead, they rent computing resources from AWS. That includes streaming platforms, collaboration tools, financial services, government systems, and countless other online services.
When AWS experienced a major outage in late 2025, the effects extended far beyond Amazon itself. Services including Slack, Zoom, Canva, Snapchat, Roblox, and many others experienced these disruptions as well.
Similarly, Let’s Encrypt issues a huge portion of the internet’s TLS certificates, helping websites establish secure connections. GitHub hosts an enormous percentage of the world’s software projects and development workflows.
More recently, AI providers have started becoming another concentration point. The internet itself does not depend on ChatGPT or Claude in the same way it depends on cloud providers or certificate authorities, but many organizations increasingly rely on these platforms for day-to-day activities.
When these services experience outages, productivity often slows down across thousands of organizations at the same time. Both OpenAI and Anthropic experienced multiple service disruptions throughout 2026, highlighting how quickly businesses have started building workflows around a relatively small number of AI providers.
The Growing Complexity of Modern Systems
For years, technology companies have been competing to add more features to their products. Your email application gets an AI assistant. Your phone receives new AI capabilities every few months. Every software update promises to do more than the one before it.
From a user perspective, some of these additions are genuinely useful, but the problem is that every new feature introduces additional moving parts behind the scenes.
A modern application is very different from the software people used twenty years ago. Back then, a program was often self-contained. Today, even relatively simple applications can rely on hundreds or thousands of software packages, external services, APIs, and cloud-based systems working together at the same time.
And with time, that complexity starts to accumulate.
You’ve probably noticed this yourself - computers are dramatically faster than they were a decade ago. Yet somehow, many applications feel heavier than the software they replaced.
Part of this comes from what developers often refer to as software bloat - companies keep adding functionality to their existing product because new features are easier to market than stability improvements. Nobody runs an advertising campaign around reducing technical debt or simplifying backend infrastructure. But AI-powered search, collaboration tools, assistants, and dashboards are much easier to sell.
The consequences become even more apparent when you look at how modern services are built.
Suppose you open your banking application. At first glance, it feels like you’re communicating directly with your bank. But the request might pass through content delivery networks, authentication providers, cloud infrastructure, and several other third-party systems before you ever see your account balance.
A lot of the time, none of this matters because everything works, but when one component fails, the effects don’t always remain isolated.
Researchers studying distributed systems have repeatedly documented what are known as cascading failures. A problem in one service can spread into another service, which then affects another, creating a chain reaction that becomes increasingly difficult to predict and diagnose.
And recently, Artificial Intelligence has been added on top of all this. Every company is in a race to shove more “AI powered” features into their products which creates even more dependencies that didn’t exist a few years ago.
The Volunteers Holding Up the Internet
Another weakness that often goes unnoticed is how much of the internet depends on software maintained by people many users have never heard of.
A huge portion of the internet also depends on open-source software projects that are freely available for anyone to use.
OpenSSL is one example. The software helps secure communications across millions of websites and online services. For years, despite being used throughout much of the internet, the project operated with limited funding and was maintained by a surprisingly small team.
In 2014, researchers discovered Heartbleed, one of the most significant internet security vulnerabilities in recent history. The flaw affected a huge number of systems around the world and exposed how much critical infrastructure depended on a project that lacked the resources many people assumed it had.
A similar story played out years later with Log4j. People didn’t even know about its existence until the Log4Shell vulnerability was discovered in 2021. Yet the software was deeply embedded inside enterprise systems, cloud platforms, government networks, and business applications around the world.
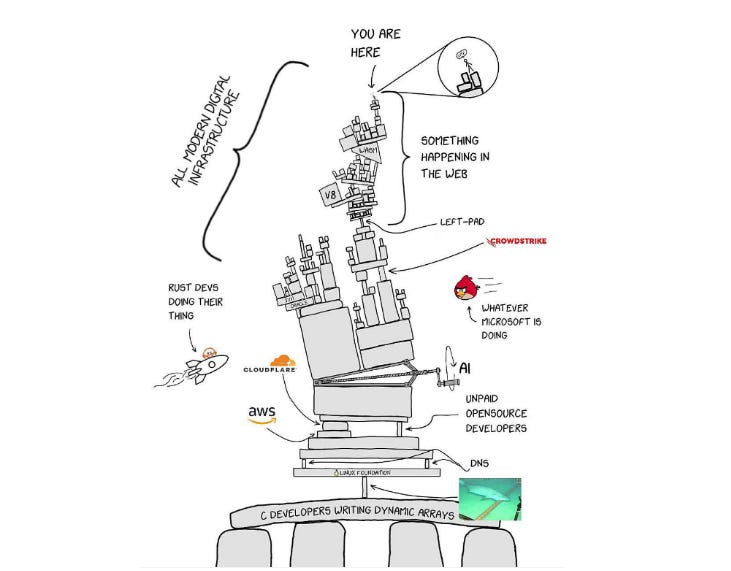
Neither OpenSSL nor Log4j is an unusual example, and the same pattern is everywhere.
Large portions of the internet depend on software maintained by small groups of developers, nonprofit organizations, and volunteers. In many cases, these projects are not generating billions of dollars in revenue despite being used by companies that are.

This has become such a well-known issue that a famous XKCD comic about software dependencies is regularly referenced throughout the open-source community. The comic jokingly depicts modern digital infrastructure resting on a tiny project maintained by a random individual that nobody has heard of.
The Infrastructure Dependence Trap
At this point, a reasonable question starts to emerge.
“If companies know they’re becoming dependent on a small number of providers, why don’t they simply move elsewhere?”
The answer is that leaving is much harder than joining.
You can see a smaller version of this in consumer technology as well.
Suppose you use an iPhone. Chances are you’re also using iCloud, AirPods, Apple Photos, Apple Notes, Apple Watch, and several other Apple services. None of these products are impossible to replace, but doing so requires time, effort, and often a willingness to change habits you’ve built over years.
The same thing happens with Google’s ecosystem. Gmail connects to Google Drive. Google Photos connects to your phone. Chrome syncs across devices. Everything becomes interconnected.
Now imagine that same problem on a much larger scale.
Companies spend years building systems around platforms like AWS, Azure, Google Cloud…etc. Applications are designed around specific services. Employees are trained to use particular platforms and workflows.
With the passage of time, entire businesses become tied to the ecosystems they started with.
Moving away isn’t impossible, but it can take months or years of planning, testing, and migration. In some cases, organizations discover that leaving creates more disruption than staying.
This is often referred to as vendor lock-in - the deeper an organization becomes embedded inside an ecosystem, the harder it becomes to leave. And because of that, many companies continue relying on the same providers even when they are uncomfortable with how dependent they’ve become.
The Risks Extend Beyond Consumer Technology
Up until now, most of the examples we’ve discussed have focused on websites, applications, and online services, but the consequences extend much further than that.
Modern cloud infrastructure now supports healthcare systems, financial institutions, transportation networks, educational platforms, and government services. Many of the systems that societies rely on every day are increasingly built on the same digital foundations.
Suppose some outage happens and a hospital loses access to critical systems, the consequences are very different.
Over the past several years, outages involving cloud providers have repeatedly affected organizations far beyond the technology sector. Hospitals have experienced disruptions to scheduling systems and patient records. Banks and payment providers have dealt with service interruptions. Government agencies have experienced outages affecting public services and internal operations.
The exact impact varies from incident to incident, but the bigger trend is becoming difficult to ignore - more and more critical services are becoming dependent on the same underlying infrastructure and as the concentration increases, failures have the potential to affect much larger portions of society than they did in the past.
Why These Risks Matter Beyond Technology
It’s hard to ignore the fact that more services are being consolidated onto the same cloud providers. More organizations are becoming dependent on the same platforms. More systems are becoming interconnected.
None of this guarantees a disaster, but it does increase the consequences when something eventually goes wrong.
We’ve already seen glimpses of what that can look like. Cloud outages have taken thousands of services offline simultaneously. Cyberattacks have disrupted supply chains and critical infrastructure. Undersea cables have been damaged by accidents, natural disasters, and geopolitical tensions, affecting connectivity across entire regions.
And that’s before we start considering scenarios involving multiple failures occurring at the same time.
Suppose a major cloud provider experiences a significant outage while a cyberattack is actively targeting connected systems. Or imagine a geopolitical conflict affecting data centers, internet exchanges, or critical communication infrastructure. Individually, each of these events is manageable. Together, they become much harder to predict and that’s where the real danger lies.
Reducing the Impact on Yourself
By now, you might be wondering what any individual can actually do about this.
The reality is that most people are not going to build their own infrastructure, run their own data centers, or completely disconnect from large technology platforms. Modern life simply doesn’t work that way anymore.
What people can do is reduce how dependent they become on any single service.
One simple example is keeping backups of important information. Many people assume that cloud services are permanent, but outages happen, accounts get locked, companies shut down products, and mistakes occur. If something is genuinely important, it’s usually worth keeping a copy somewhere under your own control as well.
It’s also worth paying attention to which services you rely on most. Some important questions which you should ask yourself are:
If your email provider suddenly became unavailable tomorrow, what would happen?
If your cloud storage stopped working for a day, could you still access important documents?
If your password manager experienced an outage, would you still be able to access critical accounts?
Most folks never think about these questions until something breaks. A small amount of preparation can often take you a long way.
Where This Leaves Us
If there’s one thing I hope this article showed, it’s that modern technology is often far less independent than it appears.
The internet gives the impression of being a vast, distributed network made up of millions of different services. And on the surface, that’s true.
But underneath that surface, many of those services depend on the same infrastructure and the same organizations. That doesn't mean the internet is on the verge of collapse. But it does mean that stability isn't the same thing as resilience.
For years, technology has become so capable. At the same time, many of the systems we depend on have become increasingly interconnected, which we never notice because everything works just fine. It's usually only during an outage that we get a glimpse of how much depends on the same underlying foundations.
As individuals, there is only so much we can do. The larger questions around infrastructure concentration, competition, and regulation will ultimately be decided by governments, companies, and policymakers.
What we can do is understand the systems we rely on, reduce unnecessary dependence where possible, and prepare for the reality that outages are not exceptions. They’re part of how complex systems behave.